multi 패러다임 언어
파이썬은 multi 패러다임 언어입니다. 즉 객체형 방식과 함수형 방식을 동시에 사용할 수 있습니다.
note)
객체지향 프로그래밍 : 프로그램을 상호작용하는 객체들의 집합으로 봅니다.
함수형 프로그래밍 : 프로그램을 상태값을 지니지 않는 함수들의 연속으로 봅니다.
동적 타이핑 언어
파이썬은 동적 타이핑 언어입니다. (dynamic typing language)
즉, 객체의 타입을 명시적으로 지정하지 않고, 런타임에서 객체의 타입을 설정하도록 하는 것입니다.
그렇기 때문에 타입을 신경쓰지 않고 코딩이 가능합니다.
아래 코드는 파이썬의 대표적인 동적 타이핑이라는 특징을 잘 나타내줍니다.
|
1
2
3
4
5
6
|
def add(a, b):
return a + b
print(add(1, 3)) # 4
print(add('item', '4')) # 'item4'
print(add([1, 2], [3, 4])) # [1, 2, 3, 4]
|
cs |
하지만 다음과 같은 코드는 타입명이 맞지 않기 때문에 TypeError가 발생합니다.
|
1
|
add('item', 4) # TypeError!
|
cs |
TypeError: can only concatenate str (not "int") to str
if문으로 타입이 동일한 경우에만 출력하도록 해도 오류는 여전합니다.
동적 타이핑 언어인 파이썬을 정적 타이핑 방식으로 사용하기 위한 다음과 같은 방식이 있습니다.
Type Annotation 문법, mypy, typing (하이퍼링크로 공식 문서를 달아 놓았습니다.)
mypy는 ~.py 문서를 검사한다고 생각하면 되고,
typing은 구현 단계 자체에서부터 정적 타이핑 방식으로 사용하는 것 같습니다.
하지만 실수를 줄이기 위해서라는 이유 빼고는 굳이 파이썬을 정적 타이핑 방식으로 사용하는 이유는 잘 모르겠습니다.
아무튼 이 동적 타이핑이라는 것은 결국 내부적으로 타입을 정의해주는 단계를 포함해주는 것이기 때문에, 속도가 필연적으로 느려질 수밖에 없습니다.
그럼에도 불구하고 파이썬을 사용하는 이유는...
Life is too short, you need python.
1) 효과적입니다. (방법론적 관점에서)
2) 효율적입니다. (시간적으로)
결론적으로 생산성이 높아지죠.
연산자 오버로딩
python은 객체지향기법의 overloading이 없다? 아닙니다. 연산자 오버로딩이 가능합니다.
note) 오버로딩은 메소드 오버로딩과 생성자 오버로딩이 있습니다. 같은 이름의 함수를 여러 개 정의하고, 매개변수의 유형과 개수를 다르게 하여 다양한 유형의 호출에 응답하게 합니다. 즉 간단히 말하면, 메소드의 '중복 정의'를 뜻합니다.
파이썬에서 클래스를 선언할 때 여러 개의 동일한 메소드를 파라미터를 달리하는 방식으로 선언할 수 없기 때문에 (자바에서는 가능하다.) 이러한 오해가 생기는 듯합니다.
파이썬에서 우리는 어떤 연산자와 함수의 동작을 똑같이 수행하는 메소드를 정의할 수 있습니다.
이러한 연산자를 메소드로 정의하는 것을 우리는 연산자 오버로딩이라 부릅니다.
연산자 오버로딩은 프로그래머가 정의내린 메소드에 내장 연산자를 사용하여 정의합니다.
메소드 앞 뒤에 밑줄 두개(__)를 이용하여 정의합니다. (이를 magic method라고도 부릅니다.)
파이썬에서 사용되는 모든 연산자들은 매직 메소드로 정의하여 오버로딩 가능합니다.
- __add__(self, other) : 이항 + 연산자(A + B, A += B)
- __sub__(self, other) : 이항 - 연산자(A - B, A -= B)
- __mul__(self, other) : 이항 * 연산자(A * B, A *= B)
- __truediv__(self, other) : 이항 / 연산자(A / B, A /= B)
- __floordiv__(self, other) : 이항 // 연산자(A // B, A //= B)
- __mod__(self, other) : 이항 % 연산자(A % B, A %= B)
- __pow__(self, other) : 이항 연산자(A B, pow(A, B))
- __lshift__(self, other) : 이항 << 연산자(A << B, A <<= B)
- __rshift__(self, other) : 이항 >> 연산자(A >> B, A >>= B)
- __and__(self, other) : 이항 & 연산자(A & B, A &= B)
- __xor__(self, other) : 이항 ^ 연산자(A ^ B, A ^= B)
- __or__(self, other) : 이항 | 연산자(A | B, A |= B)
- __not__(self) : 단항 ~ 연산자(~A)
- __abs__(self) : 단항 절대값 연산자(abs(A))
비교 연산자들도 오버로딩 가능합니다.
- __lt__(self, other) : < 연산자 - Less than(self가 other 미만인지)
- __le__(self, other) : <= 연산자 - Less than or equal to(self가 other 이하인지)
- __gt__(self, other) : > 연산자 - Greater than(self가 other 초과인지)
- __ge__(self, other) : >= 연산자 - Greater than or equal to(self가 other 이상인지)
- __eq__(self, other) : == 연산자 - Equal to(self와 other가 같은지)
- __ne__(self, other) : != 연산자 - Not equal to(self와 other가 다른지)
연산자 오버로딩을 이용했을 때의 장점은 코드를 읽기 쉬워지고 유지보수하는 데에도 도움이 됩니다.
Glue language
파이썬은 언어보다는 specification입니다.
Jython : Java로 만든 파이썬
Cython : C와 파이썬의 중간형태, high performance
micropython : embeded, 어셈블리
pypy : 파이썬으로 만든 파이썬, python보다 5배 빠릅니다.
한편 파이썬은 본래 C언어로 만들어졌기 때문에, pointer 속성을 가집니다.
Dynamic language
언어가 복잡해지면서 파이썬은 많은 기능을 담고 있다.
파이썬은 C보다 5~10배 느리다고 알려져 있습니다.
그에 대한 해결책은
1) glue(C와 연결) 예) numpy는 내부적으로 상당 부분 C나 포트란으로 작성되어 실행속도가 빠른 편입니다.
2) HW 연동 예) tensorflow에서는 GPU 병렬처리를 지원합니다.
keyword
파이썬의 키워드 개수는
|
1
2
|
import keyword
len(keyword.kwlist)
|
cs |
이렇게 하면 알 수 있다.
총 35개!
그래서 8개의 statement(문)가 존재한다.
할당
파이썬에서의 할당은 이런 식이다.
identifier = expression
expression은 '수식'이라는 뜻으로 하나 이상의 값으로 표현될 수 있는 코드를 말한다.
그러한 expression은 identifier에 저장될 수 있고,
expression이면 오른쪽에 올 수 있다!
|
1
2
3
4
|
a = 1+2
문근영 = 1
print(문근영) #1
|
cs |
이런 것도 가능하지만 PEP에서 권장되는 방식은 아니다.
|
1
|
b = 3 if a>0 else 5
|
cs |
이 if문도 하나의 값으로 표현될 수 있기 때문에 expression이다.
한편 x라는 identifier를 지정하지 않은 상태로 print하게 되면 어떤 일이 발생할까?
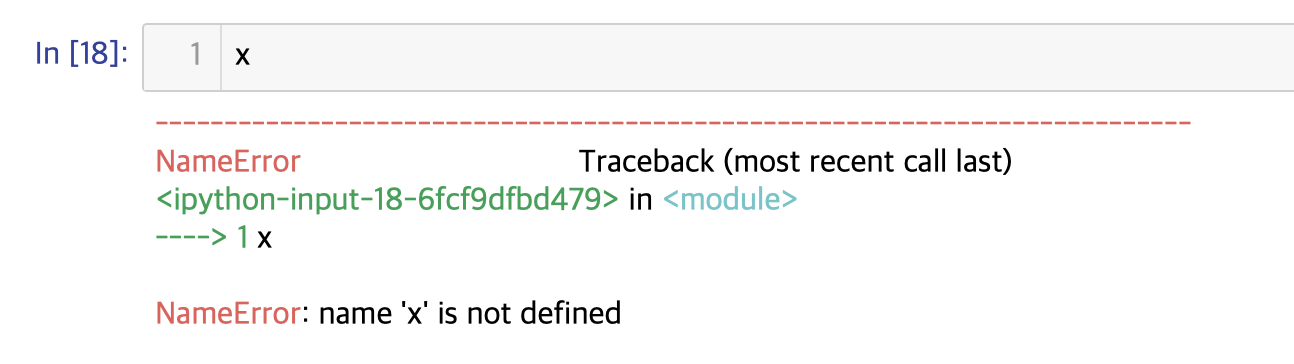
NameError: name 'x' is not defined라는 에러가 발생한다. 지정되어 있는 변수 목록에 x라는 변수가 존재하지 않기 때문에 발생하는 에러이다.
파이썬 노트북에서는 다음과 같이 변수 보기를 지원한다.

%whos는 type, data까지 표의 형태로 보여주며,
%who_ls는 variable의 목록을 list()로 반환한다.
cf) %는 파이썬 노트북에서 사용되는데, 이를 포함한 명령어는 그 셀 전체에 영향을 미친다.
id()를 통해 해당 변수가 어디에 저장되어 있는지 알 수 있다.

hex(id())를 통해 id값을 16진수로 확인할 수 있다.

정확히 말하면, id()는 주소값의 첫번째 주소를 출력한다. mutable type의 경우 여러 개의 id를 사용해야 하는 경우가 있는데, 이런 경우에 id()를 출력하게 되면 그 list의 첫번째 주소가 출력되는 셈이다.

같은 변수에 값을 재할당(같은 값을 다른 값으로 바꿈)하거나, 다른 변수에 같은 값을 할당할 때에 기본적으로 저장 공간은 달라진다.
한편 -5~256의 경우에는 바뀌지 않는데, 이를 interning이라고 한다.
note) Interning이란 이미 생성된 객체를 재사용하는 것을 말하는데, 보통 Immutable 객체에 대해 Interning을 사용한다. 파이썬은 기본적으로 몇가지 제한된 경우에 대해 디폴트로 Interning을 사용(문자열의 경우 20자 미만의 공백을 포함하지 않는 문자열, 정수의 경우 -5부터 256 사이의 정수)하고 있으며, 또한 개발자가 필요한 경우 함수를 써서 Interning을 지정할 수도 있다. 아주 많이 사용되는 Immutable 객체의 경우 인터닝 기법을 사용하게 되면 메모리를 줄일 수 있는 효과가 있다.
파이썬의 자료형
(1) 숫자형
1) int
: 파이썬에서의 int는 크기에 상관없다. 즉 overflow가 없다.
파이썬에서는 정수범위를 벗어나면 dynamic하게 확장시켜준다. 즉, overflow가 있긴 있는데 다른 방식으로 처리를 해준다.
한편 동적으로 계속 할당하기 때문에 내부처리속도는 떨어진다.
또 int 중간에 _가 있으면 내부적으로 제외하고 처리한다.
100_000_000는 그렇기 때문에 식(expression)이다.
하나의 값이기 때문에 식으로 간주한다. 즉, 오른쪽에 올 수 있다.
|
1
2
3
4
|
a.__abs__() # 절댓값
-1.__abs__() # Syntaxerror
-1 .__abs__() # no error
(-1).__abs__() # no error
|
cs |
__abs__() 메서드는 절댓값을 리턴한다.
한편 변수 뒤에 사용하는 것이 아니라 정수 바로 뒤에 이 함수를 사용할 경우 Syntaxerror가 나는데,
그 이유는 정수형 뒤에 .을 쓸 경우 파이썬의 연산자 우선순위 때문에 이 전체를 float으로 생각하게 된다.
이를 해결하기 위해서는 한 칸을 띄우거나, 괄호로 연산자 우선순위를 intercept한다.
2) 부동소수점 float
빅데이터에서는 인공지능을 활용하는 경우 때문에 정수분석보다 부동소수점에 대한 분석이 압도적으로 많다.
한편 부동소수점에 대해서는 언어마다 지정한 규칙이 있고, 그로 인해 전혀 다른 이슈가 발생한다.
파이썬에서 소수에 대한 정보를 보려면 다음과 같이 한다.

파이썬에서 실수 자료형 float의 max값은 1.7976931348623157e+308이다.
그런데 파이썬의 float은 전혀 다른 숫자 형식을 지원한다.
1. 무한대
|
1
2
3
|
x = float('infinity')
x = float('inf')
print(x) # inf
|
cs |
x를 프린트하게 되면 inf가 출력된다.
또 실수 자료형의 범위를 벗어난 값을 출력하려고 해도 inf가 출력된다.

무한대에 1을 더한 값은 무한대이기 때문에

2. nan
not a number, 숫자가 아닌 값이다.
이 역시 부동소수로 표현된다.

부동소수점은 컴퓨터로 정확히 표현할 수 없다. 그 자체가 복잡한 연산과정을 포함하고 있기 때문에 근사값만 표현 가능하다.
이는 다른 언어에서도 비슷하게 나타나는 문제로써, decimal, fractions 등 파이썬 패키지로 해결 가능하다.

3) 복소수 complex
복소수는 실수부와 허수부로 나뉘고, 허수부는 j를 붙여 표현한다.
다음과 같이 선언할 수 있다.
|
1
|
a = 3 + 2j
|
cs |
complex형에서 사용할 수 있는 메서드들 : imag, real, conjugate()

4) bool
True는 1, False는 0의 값을 가진다.
bool 자료형은 100% 숫자처럼 행동한다.

그럼 True는 1과 같을까?

값은 같고, 저장된 공간은 같지 않다.
참고
'language' 카테고리의 다른 글
| 데이터의 입력과 출력 (0) | 2019.09.24 |
|---|---|
| 파이썬과 private attribute (0) | 2019.09.21 |
| 파이썬의 class와 self (0) | 2019.09.21 |
| 파이썬을 파이썬답게 (0) | 2019.09.16 |
| 정렬 - list.sort(), sorted() (0) | 2019.09.06 |
